MCMC: A (very) Beginnner’s Guide
Imad Pasha | 2017 (Updated May 2020)
In this tutorial, I’ll be going over the basics of MCMC and running an MCMC on some data. I’m not going to spend much time on the complicated bayesian math that goes into it, but for more detail you can check out http://dan.iel.fm/emcee/current/user/line/
For the purposes of this tutorial, we will simply use MCMC (through the Emcee python package), and discuss qualitatively what an MCMC does.
2020 Update: I originally wrote this tutorial as a junior undergraduate. I am now going through and updating things here and there — but will try to keep the level the same. I plan to release a tutorial on writing your own MCMC sampler from scratch very soon!
So what is MCMC?
MCMC stands for Markov-Chain Monte Carlo, and is a method for fitting models to data. Update: Formally, that’s not quite right. MCMCs are a class of methods that most broadly are used to numerically perform multidimensional integrals. However, it is fully true that these methods are highly useful for the practice of inference; that is, fitting models to data.
MCMC is, most simply, a sampler. What does that mean? Experts in the field (i.e., Daniel Foreman-Mackey and David Hogg) will tell you that MCMC should *not generally * be used to locate the optimized parameters of some model to describe some data — there optimizers for that. What MCMC really shines at is in being able to sample from the posterior distribution around those optimum values in order to generatively model the data. In practice, this allows you to obtain better, more robust uncertainties on your parameters, to understand multi-modalities or covariances in your data, and marginalize out nuisance parameters that you don’t care about, but nevertheless need to include in your modeling to obtain accurate results.
The fundamental process of running an MCMC in this mode is to compare generated models against data. Those models are generated by a set of parameters, and our goal is usually to sample from the set of parameters that produces the models that well-fit our data.
It’s important to note that in order to be feasible, the MCMC process is inherently Bayesian as opposed to frequentist. What this means, practically, is that our MCMC requires us to impose what are known as priors on our parameters. These priors encode information we as modelers think we already know about the system we are modeling. For example, if I were constructing a model for the sun, I might impose a prior that the temperature at the core is within a certain range, because I know from observations that nuclear fusion is occurring, and that this can only happen above certain temperatures. Update note: The idea of priors often sketches people out. But don’t be afraid. The adoption of priors is a necessity of the method, but it does not impel you to adopt highly restricted, informative priors. You can easily adopt wide, flat priors, and for the most part, good data ends up swamping out whatever the priors were anyway.
We then calculate the probability of our model given our data. In the lingo of statisticians, this quantity is
and is called the Posterior Probability. it is calculated using some rearrangement of Bayes theorem as
The other terms here are
- : the probability of the data given the model (this is called the likelihood)
- : the probability of our model (known as the prior).
- : The probability of the data (often called the evidence).
Update note: The evidence is hard to compute. Some codes do it, but for the most part we can ignore it as a normalizing constant offset, and focus on the numerator.
What an MCMC does is allow you to estimate (sample) the posterior distribution (the LHS of the equation). This comes down to numerically integrating the RHS, for some given expectation value. For example, if we want the expectation value of (the parameters of our model), we’d want to compute
Or, for any function of , ,
When these integrals are analytically intractable (generally because is a complex function we know how to evaluate at some but not how to integrate, we approximate the integral by sampling, e.g.,
Update note: The evidence is hard to compute. Some codes do it, but for the most part we can ignore it as a normalizing constant offset, and focus on the numerator.
The process actually running an MCMC in this framework is something like this:
- Establish a function that outputs a model given a set of input parameters
- Establish an ensemble of walkers defined by a vector that contains a set of parameters as used by the model-generating function. For example, if we constructed a simple model that predicts the number of planets in an extrasolar system based on the host star’s metallicity , mass , and temperature , a vector would look like:
- One can imagine a “grid” of possible values for , within the prior ranges we’ve chosen to vary over.
- Every walker will now begin exploring the parameter space. To do this, each walker takes a “step” to a new value of and generates a model with that . It then compares the model to the given data, usually via a simple -type check:
- The MCMC then checks the ratio of the Likeliness generated by the new model with the data vs. the current model. Generally speaking, if the new location produces a better match to the data, the walker moves there and repeats the process. If the new location is worse, it retreats to its previous position and tries a new direction. Sometimes, even when a new position is good, the walker stays put, or if the new position is bad, the walker goes — this is set by what’s called the acceptance ratio, and it makes sure that walkers don’t all get trapped on individual peaks of high probability.
- Eventually, the walkers all begin climbing towards the regions of highest “likeness” between the models generated in the data.
At the end of the process (known as a production run), we have what is known as a posterior distribution or chain. Every walker keeps a record of every vector it accepted, and the likelihood of the model given the data at that value of .
By some complicated mathematics I won’t get into, this distribution, assuming the MCMC runs long enough to converge reasonably (that is, the distribution of walkers is not changing en masse as a function of step number), represents a sample of reasonable models to describe our data.
It’s reasonable to wonder what the “best fit” is. But rememeber that MCMC is not a “fitter,” it is a “sampler.” MCMC can’t tell us that parameter set is the “best” - one our models will have the numerically highest value of “likeness” to the data, but if we re ran the MCMC, or ran it longer, etc., we will get different answers. What MCMC is better at telling us is something like “If you draw 100 random models out of the posterior distribution, the spread in those models is representitive of our ability to constrain the parameters in those models.”
The easiest way to see this is to jump in with an example!
Fitting the Earth’s Milankovich Cycles
Located in this directory is a file containing the temperature change, age, deuterium content, etc., of the Earth’s atmosphere over the last several million years, calculated from measurements of ice-core samples. For the purposes of this tutorial, we will be interested in only the age and temperature columns.
The file is called ‘ice_core_data.txt’, and the ages and are in the third and fifth columns, respectively. Load the data and plot the Temperature deviation (from average) against age to see what we will be trying to fit in this tutorial.
import numpy as np
import matplotlib.pyplot as plt
import emcee
import corner
%matplotlib inline
plt.rcParams['figure.figsize'] = (20,10)
ice_data = #Load Data here
#Plot age vs temperature
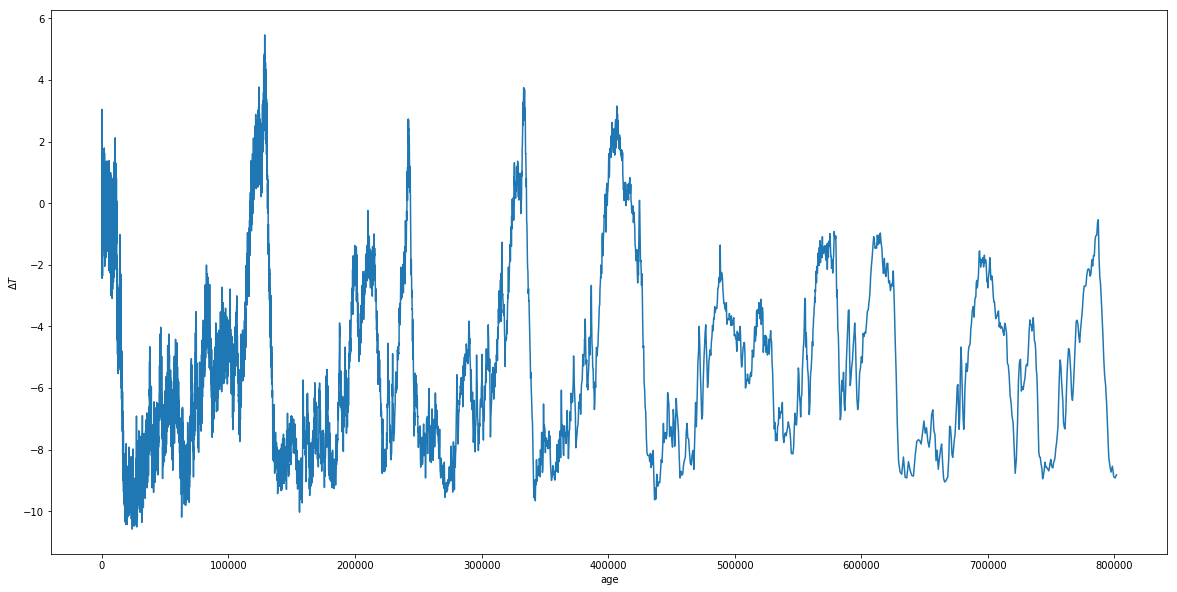
Great. Now, we can see that the temperature of Earth fluctuates a lot over its history, but that those fluctuations seem fairly periodic. It turns out, these fluctuations are due to combinations of small, but important periodic changes in the Earth’s tilt (obliquity), rotational precession, orbital precession, eccentricity, and ecliptic inclination. Three of these effects were studied extensively by Milutin Milankovich and have come to be named after him. While not the only effects, they are three of the primary ones driving the fluctuations we see above.
Those three effects are the obliquity, rotational precession, and eccentricity. For more on these effects, you can check out the wikipedia article: https://en.wikipedia.org/wiki/Milankovitch_cycles
From the article, we can see that the periods of the Milankovich cycles are approximately 26,000 years, 41,000 years, and 100,000 years. While our model will actually end up fitting our periods for us, but having these numbers in mind will allow us to shorten our MCMC run by introducing good , which are a priori limitations on the allowed parameter values. For example, if you are simulating galaxy spectra, the age of the galaxy as a free parameter should not be allowed to be greater than the age of the universe. Why let the MCMC spend the time fitting models that are unphysical anyway?
We can create a basic model for describing the above fluctuations as a sum of three sinusoids, which have different amplitudes and periods corresponding to roughly the Milankovich cycles. This won’t work perfectly, but will be good enough for our purposes. Our model will be of the form
where and are the parameters we will be fitting for.
Setting up the MCMC
First, of course, you need an mcmc code- I will be using emcee, which can be installed using pip install emcee.
We will be creating four functions for this MCMC run. The first is straightforward, and is known as the model. The model function should take as an argument a list representing our vector, and return the model evaluated at that . For completion, your model function should also have your age array as an input, which here we can set to default to the age array defined above. Create your function below:
def model(theta,age=age):
a1,a2,a3,p1,p2,p3,T0 = theta
model = #your code here
return model
We now need a function referred to as lnlike(). This function takes as an argument theta as well as the , , and of your actual theta. It’s job is to return a number corresponding to how good a fit your model is to your data for a given set of parameters, weighted by the error in your data points (i.e. it is more important the fit be close to data points with small error bars than points with large error bars). We will use the following formulation to determine this number- translate it to a function in python below:
def lnlike(theta, x, y, yerr):
LnLike = #implement formula above
return LnLike
The next function we need is one to check, before running the probability function (last one defined) on any set of parameters, that all variables are within their priors (in fact, this is where we set our priors).
The output of this function is totally arbitrary (it is just encoding True False), but emcee asks that if all priors are satisfied, 0.0 is returned, otherwise return -np.inf. Its input is a vector.
Set up an lnprior function that specifies bounds on and . Reasonable bounds on the amplitudes can be drawn from the plot above (the amplitudes individually can’t be greater than the overall amplitude of the final fluctuations, and must be within the upper and lower bounds of the data we see). Priors on the periods are tricker, I suggest going for around ten thousand years around the known Milankovich cycle periods given above- we expect the values to be close to these. (We will talk a bit later about evaluating from “walker plots” whether our priors might not have been great).
def lnprior(theta):
a1, a2, a3, p1, p2, p3, T0 = theta
if #apply conditions on priors here
return 0.0
else:
return -np.inf
The last function we need to define is lnprob(). This function combines the steps above by running the lnprior function, and if the function returned -np.inf, passing that through as a return, and if not (if all priors are good), returning the lnlike for that model (by convention we say it’s the lnprior output + lnlike output, since lnprior’s output should be zero if the priors are good). lnprob needs to take as arguments theta, x, y, and , since these get passed through to lnlike.
def lnprob(theta, x, y, yerr):
lp = #call lnprior
if not #check if lp is infinite:
return -np.inf
return lp + lnlike(theta, x, y, yerr) #recall if lp not -inf, its 0, so this just returns likelihood
We have one or two steps left before we can run. First, our Temperature measurements, unfortunately, have no errors provided. But we need errors for the MCMC to run, so let’s set a yerr array arbitrarily to 5% of the average temperature in our temperature array.
We will want to feed our data (x,y,yerr) in as a tuple, so set data equal to a tuple of our age, temperature and temperature error arrays.
We also need to set a value for nwalkers, which determines how many walkers are initialized in our MCMC. Let’s use 500.
We need a variable called initial, which is an initial set of guesses (this will be the first theta, where the MCMC starts). *2020 Update: Foreman-Mackey & Hogg recommend that in many cases, running an optimizer first (e.g., from scipy) is the best way to select an initial starting value.
Finally we need p0, which is the methodology of stepping from one place to a grid to the next ( I will provide this). For those interested, this is a multivariate Gaussian centered on each theta, with a small . Thus, the proposed move for each walker is general some place in N-dimensional parameter space very close to the current location.
Terr = #set to 5% of average temperature
data = (age, T,Terr)
#set nwalkers
#set niter
initial = np.array([1.0, 1.0, 1.0, 26000., 41000.,100000.,-4.5])
ndim = len(initial)
p0 = [np.array(initial) + 1e-7 * np.random.randn(ndim) for i in range(nwalkers)]
We are now ready to run the MCMC. I’ll provide the code for this, since it just amounts to looking up emcee’s documentation.
def main(p0,nwalkers,niter,ndim,lnprob,data):
sampler = emcee.EnsembleSampler(nwalkers, ndim, lnprob, args=data)
print("Running burn-in...")
p0, _, _ = sampler.run_mcmc(p0, 100)
sampler.reset()
print("Running production...")
pos, prob, state = sampler.run_mcmc(p0, niter)
return sampler, pos, prob, state
The sampler here contains all the outputs of the MCMC, including the walker chains and the posteriors. We will talk a little bit later about evaluating whether an MCMC has “converged,” but for now let’s quickly extract a random sampling of our posteriors and plot them over our data.
sampler, pos, prob, state = main(p0,nwalkers,niter,ndim,lnprob,data)
Running burn-in...
Running production...
def plotter(sampler,age=age,T=T):
plt.ion()
plt.plot(age,T,label='Change in T')
samples = sampler.flatchain
for theta in samples[np.random.randint(len(samples), size=100)]:
plt.plot(age, model(theta, age), color="r", alpha=0.1)
plt.ticklabel_format(style='sci', axis='x', scilimits=(0,0))
plt.xlabel('Years ago')
plt.ylabel(r'$\Delta$ T (degrees)')
plt.legend()
plt.show()
#sampler= main(p0)
plotter(sampler)
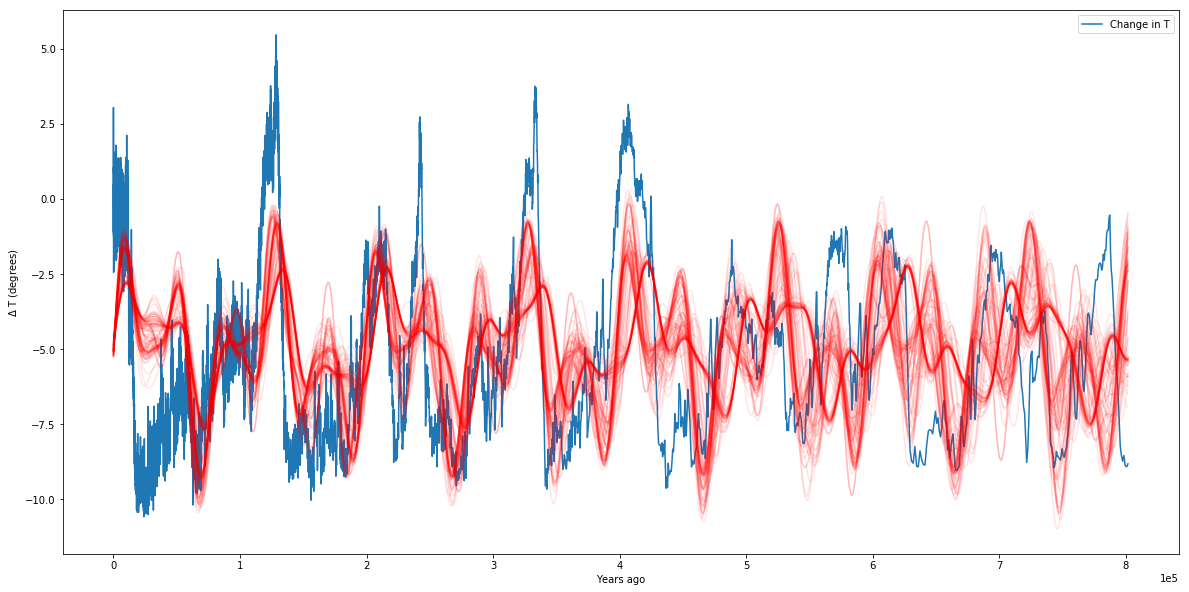
We can see from our plot that our simplistic model (of three sinusoids) is not perfect, but it does a pretty good job of matching our data. We can see that from the hundred samples we drew from the posteriors, they all seem to overlap over each other pretty well. We can see the exact values of our parameters as well:
samples = sampler.flatchain
samples[np.argmax(sampler.flatlnprobability)]
array([ 1.15798073e+00, 2.15676385e+00, 2.04568557e+00,
2.35304144e+04, 3.98365576e+04, 9.62770268e+04,
-5.26740279e+00])
samples = sampler.flatchain
theta_max = samples[np.argmax(sampler.flatlnprobability)]
best_fit_model = model(theta_max)
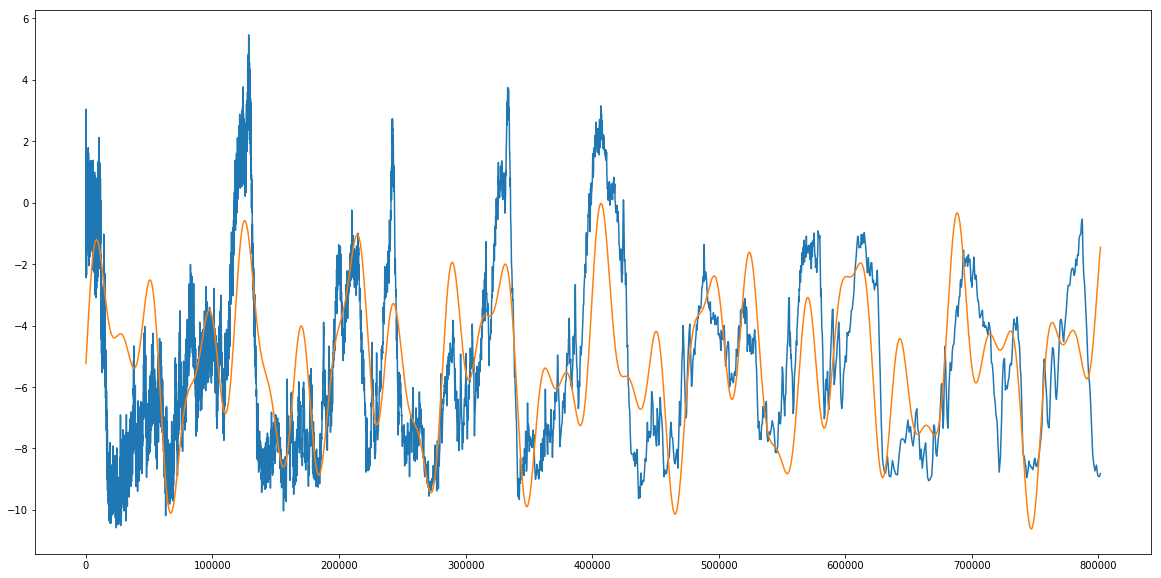
plt.plot(age,T,label='Change in T')
plt.plot(age,best_fit_model,label='Highest Likelihood Model')
plt.show()
print 'Theta max: ',theta_max
Theta max: [ 1.15798073e+00 2.15676385e+00 2.04568557e+00 2.35304144e+04
3.98365576e+04 9.62770268e+04 -5.26740279e+00]
So we find that our amplitudes are 1.15, 2.15, and 2.04 (seems about right, they should be less than around 5), we get periods of 23,530 years, 39,836 years, and 96,277 years (pretty close to our predictions of 26,000, 41,000, and 100,000 years), and a of -5.24 degrees, which we almost could’ve read straight off the graph in the first place. My simple check above just takes the averages of the posteriors, which is hardly bayesian, but we can also look at, for example, the standard deviation (spread) in posteriors.
Posterior Spread
We can use the corner.py module to visualize 1D and 2D spreads between the parameters we are testing, and get some uncertainties on our paraemter estimations.
labels = ['a1','a2','a3','p1','p2','p3','T0']
fig = corner.corner(samples,show_titles=True,labels=labels,plot_datapoints=True,quantiles=[0.16, 0.5, 0.84])

In all honesty, these look pretty awful, with bimodalities and clumps all over the place. All of this is indicative of the fact that we chose a pretty crappy model in the first place. Take a look at a1: the two peaks at different amplitudes show that we haven’t converged on a single answer, and if you look at the plot where I simply draw from the posteriors, at the very first peak you can see the two modes of amplitude. It’s possible that more walkers and more iterations could help us solve this – let’s give it a try.
Terr = 0.05*np.mean(T)
data = (age, T,Terr)
nwalkers = 240
niter = 1024
initial = np.array([1.0, 1.0, 1.0, 26000., 41000.,100000.,-4.5])
ndim = len(initial)
p0 = [np.array(initial) + 1e-7 * np.random.randn(ndim) for i in xrange(nwalkers)]
new_sampler, newpos, newprob, newstate = main(p0,nwalkers,niter,ndim,lnprob,data)
Running burn-in...
Running production...
new_samples = new_sampler.flatchain
new_theta_max = new_samples[np.argmax(new_sampler.flatlnprobability)]
new_best_fit_model = model(new_theta_max)
plt.plot(age,T,label='Change in T')
plt.plot(age,new_best_fit_model,label='Highest Likelihood Model')
plt.show()
print 'Theta max: ',new_theta_max
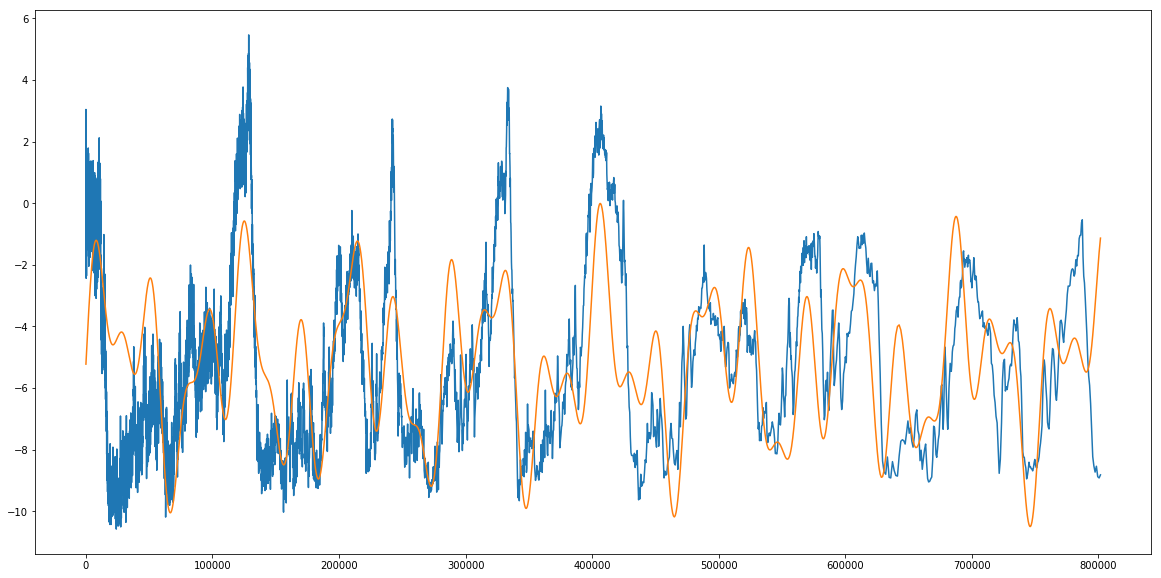
Theta max: [ 1.32723884e+00 2.07934292e+00 1.89735570e+00 2.35215810e+04
3.97328136e+04 9.61323211e+04 -5.25707013e+00]
labels = ['a1','a2','a3','p1','p2','p3','T0']
fig = corner.corner(new_samples,show_titles=True,labels=labels,plot_datapoints=True,quantiles=[0.16, 0.5, 0.84])

A lot of things still look crappy, but we can see that the secondary modes seems to be supressed – most of the models now favor a single value. So what about plotting a one sigma spread in posteriors over the theta max we plotted? Easy! All we need to do is draw a random sample from the posteriors and find the spread at each “x-value” where we evaluated our model.
def sample_walkers(nsamples,flattened_chain):
models = []
draw = np.floor(np.random.uniform(0,len(flattened_chain),size=nsamples)).astype(int)
thetas = flattened_chain[draw]
for i in thetas:
mod = model(i)
models.append(mod)
spread = np.std(models,axis=0)
med_model = np.median(models,axis=0)
return med_model,spread
med_model, spread = sample_walkers(100,new_samples)
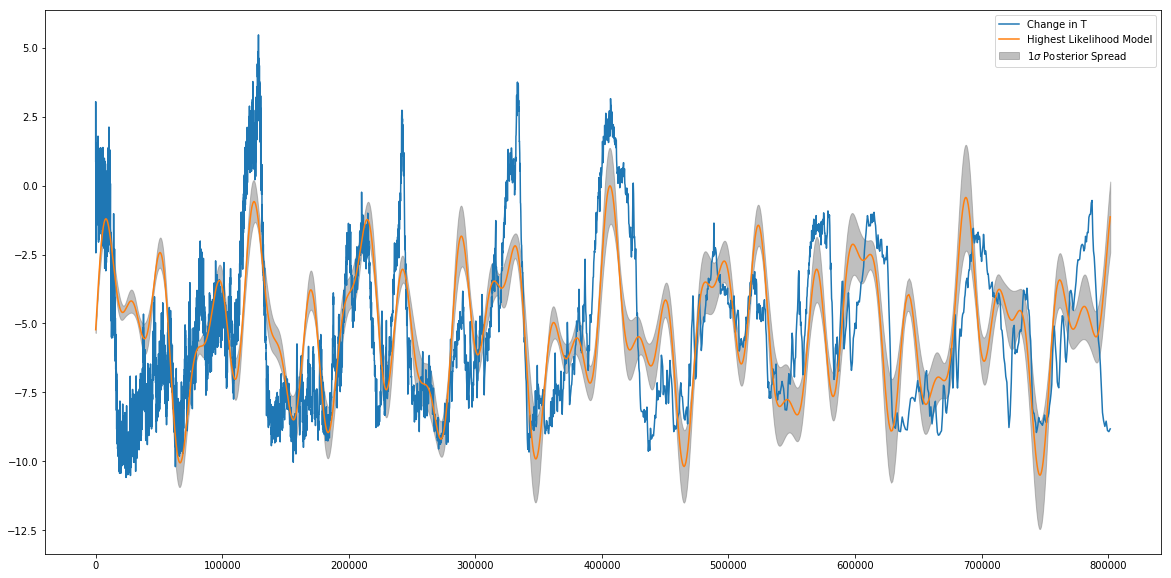
plt.plot(age,T,label='Change in T')
plt.plot(age,new_best_fit_model,label='Highest Likelihood Model')
plt.fill_between(age,med_model-spread,med_model+spread,color='grey',alpha=0.5,label=r'$1\sigma$ Posterior Spread')
plt.legend()
<matplotlib.legend.Legend at 0x109d57a10>
Note that the “Most likely” model doesn’t always have to (and sometimes doesn’t) sit at the center of this spread- the spread is around the median model, but the one that absolutely maximizes the likelihood might sit at the edge or even outside this region.
This has been an interesting test example. It’s worth noting that though our model was kind of crappy, using the data we were able to fit for the periods of the Milankovich cycles pretty accurately.
Congrats! You made it to the end of the tutorial. I hope you enjoyed it, practiced a little python, and learned something about galaxy properties. As always, feel free to contact me (post an issue on the github http://github.com/prappleizer/prappleizer.github.io ) if anything was messed up, confusing, or poorly explained.
Finally, there are numerous awesome resources out there for learning more about MCMC. The best I can recommend is the paper by Hogg & Foreman Mackey. Additionally, I’m about to release a new tutorial on writing your own Metropolis-Hastings MCMC, and applying it to real astronomical data! It dovetails nicely with a lot of what is covered in the above paper, so look out for that!